
왜 Gemini인가?
2편에서는 OpenAI(Whisper + GPT-4o + TTS)로 파이프라인을 구축했습니다. 완벽하게 동작하지만 비용이 문제입니다. 하루에 몇 번만 대화해도 월 정기결제가 필요할 수 있죠. 그런데 Google Gemini Free Tier로 이 모든 걸 공짜로 할 수 있다면?
| 2편 (OpenAI) | 이번 편 (Gemini Free) | |
|---|---|---|
| STT | Whisper API — $0.006/분 | Gemini 3.5 Flash (multimodal) — 무료 |
| LLM | GPT-4o — $2.5/1M토큰 | Gemini 3.5 Flash — 무료 |
| TTS | OpenAI TTS — $15/1M문자 | Gemini 3.1 Flash TTS — 무료 |
| API 호출 | 3회 (STT + LLM + TTS) | 2회 (STT+LLM 통합) |
| 월 비용 | $10~50+ | $0 |
핵심 아이디어: Gemini 3.5 Flash는 multimodal 모델이라 오디오를 직접 이해합니다. 별도 STT 호출이 필요 없어서 API 3회에서 2회로 줄어듭니다.
아키텍처: API 2번 호출
이전 3회 호출 구조에서 Gemini multimodal의 장점을 살려 STT와 LLM을 하나로 합쳤습니다.
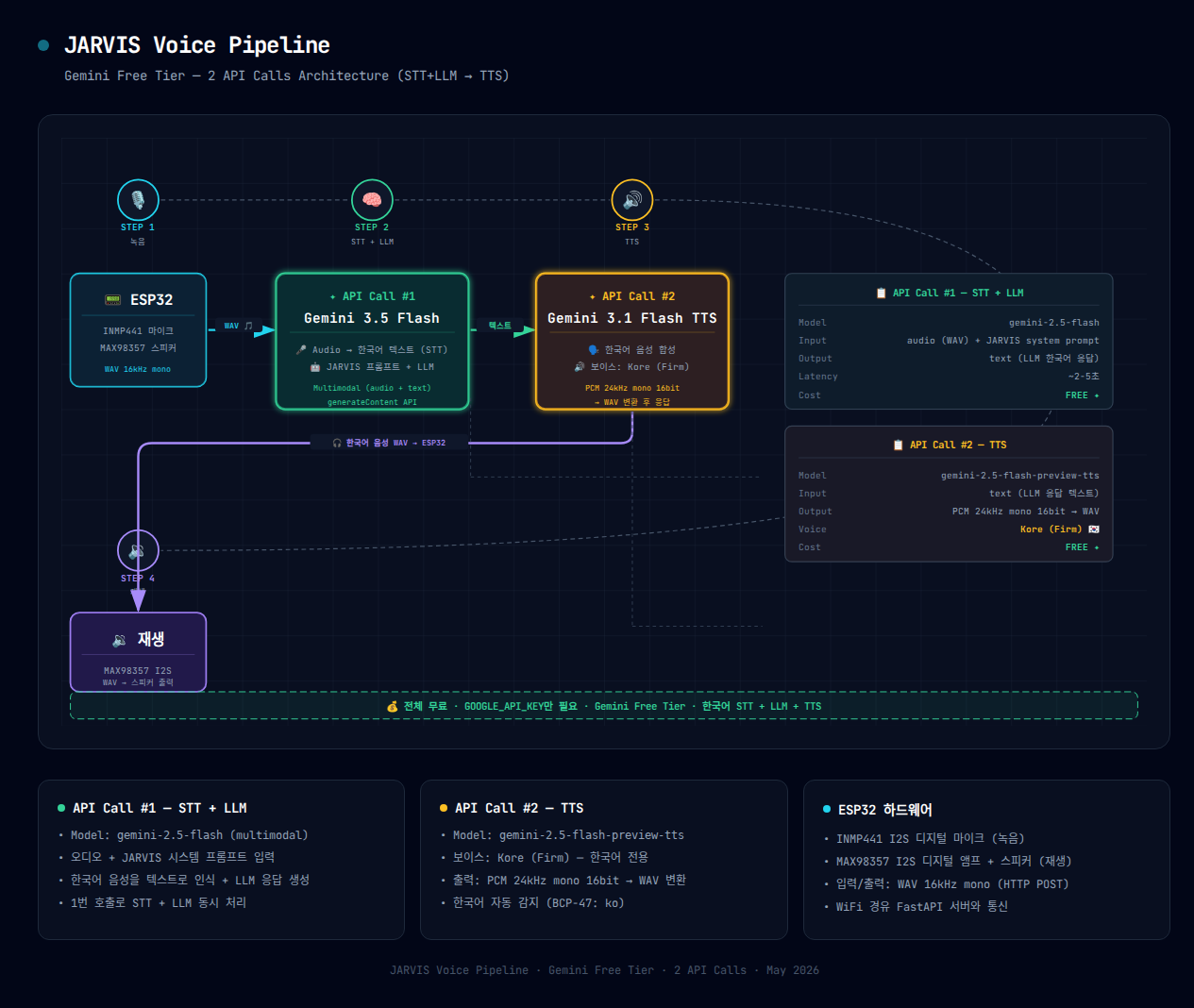
| 단계 | API Call | 모델 | 입/출력 |
|---|---|---|---|
| 🎙️ 녹음 | - | - | ESP32 INMP441 마이크 → WAV 16kHz |
| 🧠 STT + LLM | #1 | gemini-3.5-flash | 오디오 + 프롬프트 → 한국어 텍스트 |
| 🔊 TTS | #2 | gemini-3.1-flash-tts-preview | 텍스트 → PCM 24kHz → WAV |
| 🔉 재생 | - | - | WAV → ESP32 MAX98357 스피커 |
1. 전제 조건
시작하기 전에 필요한 것들입니다.
Google AI Studio API 키
Google AI Studio에서 무료 API 키를 발급받습니다. Google 계정만 있으면 됩니다.
# .env
GOOGLE_API_KEY=AIzaSy...#your-key-herePython 패키지
pip install google-genai fastapi uvicorn python-multipartgoogle-genai 패키지 하나로 Gemini의 모든 기능(STT, LLM, TTS, 이미지 생성)을 사용할 수 있습니다.
2. FastAPI 서버 구현
이전 2편의 서버를 Gemini API로 교체합니다. 코드가 오히려 더 간단해집니다.
# server.py — Gemini 2-Call Voice Pipeline
import io
import wave
import tempfile
from fastapi import FastAPI, UploadFile, File
from fastapi.responses import Response
from google import genai
from google.genai import types
app = FastAPI()
# --- 설정 ---
STT_LLM_MODEL = "gemini-3.5-flash"
TTS_MODEL = "gemini-3.1-flash-tts-preview"
TTS_VOICE = "Kore" # 한국어 Firm 보이스
# JARVIS 시스템 프롬프트
SYSTEM_PROMPT = """
너는 JARVIS(자비스)다. 아이언맨의 AI 비서처럼 동작한다.
규칙:
- 한국어로 대답한다
- 간결하게 3문장 이내로 대답한다
- 필요시 유머를 섞는다
- 모르는 건 솔직하게 모른다고 한다
- 현재 시간: {time}
"""
client = genai.Client()
# --- API Call #1: STT + LLM (multimodal) ---
def stt_llm(audio_path: str) -> str:
"""오디오를 Gemini에 보내서 텍스트 인식 + LLM 응답을 한 번에 받는다."""
import datetime
now = datetime.datetime.now().strftime("%Y년 %m월 %d일 %H:%M")
prompt = SYSTEM_PROMPT.format(time=now)
with open(audio_path, "rb") as f:
audio_bytes = f.read()
response = client.models.generate_content(
model=STT_LLM_MODEL,
contents=[
prompt,
types.Part.from_bytes(
data=audio_bytes,
mime_type="audio/wav",
)
],
)
return response.text
# --- API Call #2: TTS ---
def tts(text: str) -> bytes:
"""LLM 응답 텍스트를 한국어 음성으로 변환한다."""
response = client.models.generate_content(
model=TTS_MODEL,
contents=text,
config=types.GenerateContentConfig(
response_modalities=["AUDIO"],
speech_config=types.SpeechConfig(
voice_config=types.VoiceConfig(
prebuilt_voice_config=types.PrebuiltVoiceConfig(
voice_name=TTS_VOICE,
)
)
),
),
)
# PCM 데이터를 WAV로 변환
pcm_data = response.candidates[0].content.parts[0].inline_data.data
wav_buffer = io.BytesIO()
with wave.open(wav_buffer, "wb") as wf:
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(24000)
wf.writeframes(pcm_data)
return wav_buffer.getvalue()
# --- 엔드포인트 ---
@app.post("/api/voice")
async def process_voice(audio: UploadFile = File(...)):
with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as f:
f.write(await audio.read())
temp_path = f.name
# 1회 호출: STT + LLM
reply = stt_llm(temp_path)
print(f"JARVIS: {reply}")
# 2회 호출: TTS
wav_bytes = tts(reply)
return Response(
content=wav_bytes,
media_type="audio/wav",
headers={"X-Text-Response": reply}
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)이전 버전과 비교하면
speech_to_text()와chat_with_llm()두 함수가stt_llm()하나로 합쳐졌습니다. 코드가 줄어들고 API 호출도 1회 감소했습니다.
3. 핵심 기술 상세
API Call #1: Multimodal STT + LLM
Gemini 3.5 Flash는 텍스트와 오디오를 동시에 입력받을 수 있는 multimodal 모델입니다. 이를 활용하면 STT(음성 인식)와 LLM(지능적 응답)을 단일 API 호출로 처리할 수 있습니다.
| 파라미터 | 값 | 설명 |
|---|---|---|
| model | gemini-3.5-flash | 현재 최신 multimodal 모델 |
| contents | [텍스트, 오디오] | 시스템 프롬프트 + WAV 오디오 |
| 출력 | text | 한국어 텍스트 응답 |
이전 방식에서는 Whisper API로 음성을 텍스트로 바꾼 뒤, 그 텍스트를 다시 LLM에 넣는 2단계였습니다. Gemini는 오디오를 직접 이해하므로 이 중간 단계가 불필요합니다.
API Call #2: Text-to-Speech
Gemini TTS는 generateContent API의 response_modalities=["AUDIO"]로 호출합니다. 별도 엔드포인트가 아닙니다.
| 파라미터 | 값 | 설명 |
|---|---|---|
| model | gemini-3.1-flash-tts-preview | TTS 전용 모델 (Preview) |
| contents | 텍스트 문자열 | LLM 응답 텍스트 |
| response_modalities | ["AUDIO"] | 오디오만 출력 |
| voice_name | Kore | 한국어 Firm 톤 보이스 |
| 출력 포맷 | PCM 24kHz mono 16bit | WAV 변환 필요 |
한국어 보이스: Kore
Gemini TTS는 30개 프리빌트 보이스를 제공합니다. 그 중 Kore (Firm)는 한국어에 최적화된 보이스입니다. 이름이 "Korean"이 아니라 "Kore"인 점에 주의하세요.
| 보이스명 | 스타일 | 추천 용도 |
|---|---|---|
| Kore | Firm (단호함) | 비서, 안내방송 ⭐ 한국어 추천 |
| Puck | Upbeat (밝음) | 캐주얼 대화 |
| Charon | Informative (정보 전달) | 뉴스, 날씨 |
| Leda | Youthful (젊음) | 친근한 톤 |
| Achernar | Soft (부드러움) | 차분한 읽기 |
AI Studio의 Voice Library 앱릿에서 모든 보이스를 미리 들어볼 수 있습니다. ai.google.dev → Speech generation 페이지에서 확인하세요.
PCM → WAV 변환
Gemini TTS의 원시 출력은 PCM raw 데이터(24kHz, mono, 16bit)입니다. ESP32가 바로 재생하려면 WAV 헤더가 필요합니다.
# PCM 데이터를 WAV로 래핑
import io, wave
def pcm_to_wav(pcm_data: bytes) -> bytes:
buf = io.BytesIO()
with wave.open(buf, "wb") as wf:
wf.setnchannels(1) # mono
wf.setsampwidth(2) # 16-bit
wf.setframerate(24000) # 24kHz
wf.writeframes(pcm_data)
return buf.getvalue()4. ESP32 펌웨어 (변경 없음)
좋은 소식입니다. ESP32 펌웨어는 2편과 완전히 동일합니다. 서버 엔드포인트만 http://your-server:8080/api/voice로 바꾸면 됩니다.
// 변경 사항: 서버 URL만 수정
#define SERVER_URL "http://192.168.1.100:8080/api/voice"
// 나머지 코드는 2편과 동일이것이 이 아키텍처의 큰 장점입니다. 서버 측 AI 백엔드만 교체하면 하드웨어는 그대로 재사용할 수 있습니다.
5. 배포 및 실행
서버 실행
# 서버에서 실행
export GOOGLE_API_KEY=AIzaSy...
python server.py
# Uvicorn running on http://0.0.0.0:8080
# 다른 터미널에서 테스트
curl -X POST http://localhost:8080/api/voice \
-F "audio=@test.wav" \
--output response.wav -v테스트용 파이썬 스크립트
# test_voice.py — 마이크로 녹음 후 서버에 전송
import requests
import pyaudio
# 3초 녹음
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 16000
RECORD_SECONDS = 3
audio = pyaudio.PyAudio()
stream = audio.open(format=FORMAT, channels=CHANNELS,
rate=RATE, input=True,
frames_per_buffer=1024)
frames = []
for _ in range(0, int(RATE / 1024 * RECORD_SECONDS)):
data = stream.read(1024, exception_on_overflow=False)
frames.append(data)
stream.stop_stream()
stream.close()
# WAV 파일로 저장
import wave, io
buf = io.BytesIO()
with wave.open(buf, "wb") as wf:
wf.setnchannels(CHANNELS)
wf.setsampwidth(2)
wf.setframerate(RATE)
wf.writeframes(b"".join(frames))
# 서버에 전송
resp = requests.post("http://localhost:8080/api/voice",
files={"audio": ("recording.wav", buf.getvalue())})
print(f"JARVIS: {resp.headers.get('X-Text-Response')}")
# 응답 오디오 저장
with open("response.wav", "wb") as f:
f.write(resp.content)
print("Saved response.wav")6. Free Tier 한계와 대책
| 제한 | 내용 | 대책 |
|---|---|---|
| RPM (분당 요청) | 15 RPM | 개인 용도엔 충분 |
| RPD (일당 요청) | 1,500 RPD | 하루 약 750회 대화 가능 |
| TTS Preview | 미리보기 버전 | 프로덕션용은 아직 주의 필요 |
| 음성 품질 | 고급 TTS 대비 약간 부족 | Kore 보이스는 꽤 자연스러움 |
개인용 음성 비서라면 Free Tier로 충분합니다. 하루에 10분씩 대화해도 RPM 15 제한에 걸리지 않습니다. (보통 1회 대화 = 2회 API 호출 = 2초 이내)
7. 시리즈 전체 비교
지금까지 만들어온 JARVIS의 진화 과정을 정리해봅니다.
| 2편 (OpenAI) | 4편 (Gemini Free) | |
|---|---|---|
| STT | Whisper API (별도 호출) | Gemini multimodal (LLM과 통합) |
| LLM | GPT-4o | Gemini 3.5 Flash |
| TTS | OpenAI TTS | Gemini 3.1 Flash TTS |
| API 호출 | 3회 | 2회 (STT+LLM = 1회) |
| 월 비용 | $10~50+ | $0 |
| 필요 패키지 | openai | google-genai (하나면 끝) |
| 코드 복잡도 | 3개 함수 | 2개 함수 (더 간단) |
다음 편에서는...
지금까지 JARVIS의 핵심인 음성 파이프라인을 완성했습니다. 다음 편에서는 실제 집에 도입해보겠습니다. 스마트홈 제어, 날씨 정보, 일정 관리 등 실용적인 기능들을 JARVIS에 연결하는 방법을 다룹니다.
나만의 자비스 시리즈
| 편 | 제목 | 내용 |
|---|---|---|
| 1편 | ESP32-S3에 귀를 달자 | Wake Word 감지, 음성 녹음 |
| 2편 | STT·LLM·TTS 파이프라인 | OpenAI 기반 전체 구축 |
| 3편 | JARVIS UI | 3.5인치 터치 디스플레이 |
| 4편 | Gemini 무료로 음성 비서 완성 | Free Tier, API 2회 호출 |